An Introduction to Automata
Why are automata so interesting? Automata are so simple that they fit in many places and situations.
You can use automata
- to describe real machines (vending machines, industrial automations, etc.)
- to validate protocols1
- as a language to express constraints2
- as a basic machine learning model without much generalization power
- to get insights on entangled quantum states3
- for all kind of string search/manipulation algorithm
A deterministic finite automaton (DFA) is made of
- a finite alphabet \(\Sigma = \{a,b,\dots,z\}\)4
- a finite set of states \(Q = \{q_0,q_1,\dots,q_{N-1}\}\)
- a transition function \(\tau: Q \times \Sigma \to Q\)
- a starting state \(q_0 \in Q\)
- a set of accepting states \(F \subseteq Q\)
and it works in this way: you are given a word \(w = a_0a_1 \dots a_{n-1}\)
- the automaton is initialized at state \(q_0\)
- for each letter \(a_i\), starting from \(i = 0\), update the state to \(q_{i+1} = \tau(q_i,a_i)\)
- if the last state \(q_n\) is an accepting state (\(q_n \in F\)) then the word \(w\) is accepted otherwise it is rejected
in the end the automaton computes a function
\[f: \Sigma^\star \to \{\text{accept}, \text{reject}\}\]
The automaton is called deterministic because at each step it is in a definite state.
The state summarizes the relevant features (relevant for the final decision to accept or reject the word) of the input processed so far.
The language of an automaton is just the set of recognized words, the language recognized by a DFA is called regular.
The alphabet is different from application to application, for example:
- for modeling machine the letters are events like the pushing of a button, the activation of a sensor etc.
- for protocols they are actions performed by some party
- for string algorithms they are just characters
For example consider the following DFA

and consider the word "byyxy"

it is accepted because the automaton ends up in state \(q_4\) which is accepting.
The traversed states encode the relevant features of the word, for example state \(q_2\) says that a "b" and zero or more of "y" have been seen. State \(q_1\) means that for the purpose of further processing an "a" and a "byyx" (with any number of "y") are the same thing.
On the other hand the word "abx"

is rejected because the automaton is stuck in the non-accepting state \(q_3\).
So the automaton accepts a word if there is a path connecting the start state to the accepting state.
The same automaton can generate random words from its language by performing a random walk on its graph.
Another way to look at \(\tau\) is as a set of adjacency matrices, one for every letter \(\sigma \in \Sigma\), defined in this way
\begin{equation*} M^{(\sigma)}_{ij} = \begin{cases} 1, & \text{if } \tau(i,\sigma) = j \\ 0, & \text{otherwise} \end{cases} \end{equation*}Suppose you are given a word \(w = a_0a_1 \dots a_{n-1}\), to check if it is accepted or not you multiply the matrices corresponding to the letters
\[M^{(w)} = M^{(a_0)} \cdot M^{(a_1)} \cdots M^{(a_{n-1})}\]
the elements \(M^{(w)}_{i j}\) count the number of paths \(\#(q_i \to q_j)\)5 so if \(\#(q_0 \to q_i) = 1\) for some \(q_i \in F\) then the word is accepted, otherwise it is rejected.
This can be seen easily for a length 2 path:
\[\left[ M^{(a)} \cdot M^{(b)} \right]_{ij} = \sum_{k=0}^{N-1} \delta_{\tau(i,a), k} \delta_{\tau(k,b), j}\]
the term inside the sum is non-zero only if there is a path \(q_i \xrightarrow{a} q_k \xrightarrow{b} q_j\) (and since the automaton is deterministic there can be only one).
Take the word "byyxy" as an example, we can take
\[M^{(byyxy)} = M^{(b)} \cdot M^{(y)} \cdot M^{(y)} \cdot M^{(x)} \cdot M^{(y)}\]
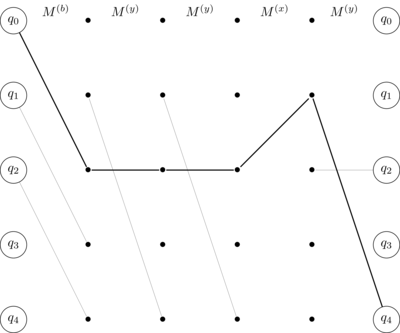
which is zero except for the entry \(q_0 \to q_4\) thus the word is accepted.
Can we make a DFA more powerful?
Imagine a machine that can be in more than one state at a time, this amounts to changing the DFA definition of \(\tau\) in this way
\[\tau: Q \times \Sigma \to \mathcal{P}(Q)\]
\(\tau\) now returns a set of states for each transition, the result is called a non-deterministic finite automaton (NFA)6.
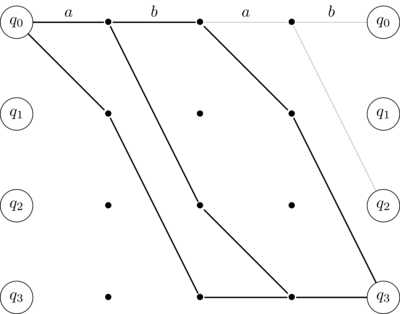
Consider for example this NFA7

note that now, starting from \(q_0\), the letter "a" leads to two states \(q_0\) and \(q_1\) also "b" leads to \(q_0\) and \(q_2\).
Consider the word "abab", the NFA performs these transitions
\[\{q_0\} \xrightarrow{a} \{q_0,q_1\} \xrightarrow{b} \{q_0,q_2,q_3\} \xrightarrow{a} \{q_0,q_1,q_3\} \xrightarrow{b} \{q_0,q_2,q_3\}\]
which end in an accepting state.
Note how the fact that the automaton can be in more than one state at once introduces multiple paths.
Now the question is:
Does this kind of flexibility lead to a richer structure of the accepted language? Does an NFA accept a larger language than a DFA?
Surprisingly the answer is NO?
Given an NFA it is always possible to build an equivalent DFA that accepts the same language through the subset construction.
The idea is to take \(\mathcal{P}(Q)\) as the set of states of the DFA (the powerset of the set of NFA's states) and to note that only a few of them will be needed.
Taking the previous example we can enumerate all the distinct states needed by the NFA
| NFA | DFA |
|---|---|
| \(\{q_0\}\) | \(r_0\) |
| \(\{q_0,q_1\}\) | \(r_1\) |
| \(\{q_0,q_2\}\) | \(r_2\) |
| \(\{q_0,q_1,q_3\}\) | \(r_3\) |
| \(\{q_0,q_2,q_3\}\) | \(r_4\) |
adding the transitions the resulting DFA is

Footnotes:
for an example in operation research see GitHub - lucamarx/pywfplan: A Python library to plan a call center workforce
I hope to write more about this when I will understand it better
we denote the set of words made by letters in \(\Sigma\) by \(\Sigma^\star\) which includes also the empty word \(\epsilon\)
since the automaton is deterministic it can be only 0 or 1
a set of states is accepted if it contains at least one accepting state
it accepts any word that contains an "ab" or a "ba"